Java
hashmap底层原理(数据结构、为什么用红黑树等)、
JDK1.8之前:
链表数组、拉链法
扰动函数:增加低位的随机性(原哈希值右移16位然后与原哈希值异或得到新哈希值),解决取模后索引位置的碰撞问题
数组长度:
n=2^m,取模操作hash%n等价于(n-1)&hashJDK1.8之后:链表长度过长会自动转成红黑树,减少搜索时间
ArrayList与LinkedList区别
Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构
Jvm内存模型
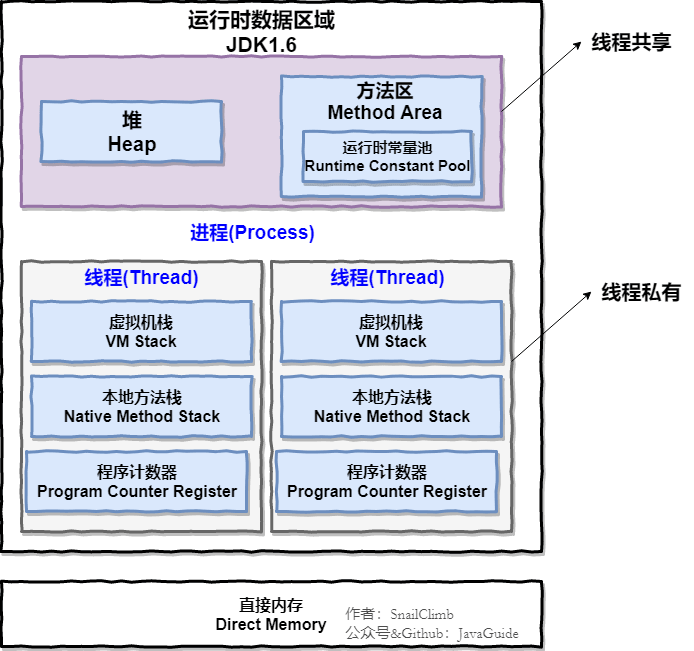
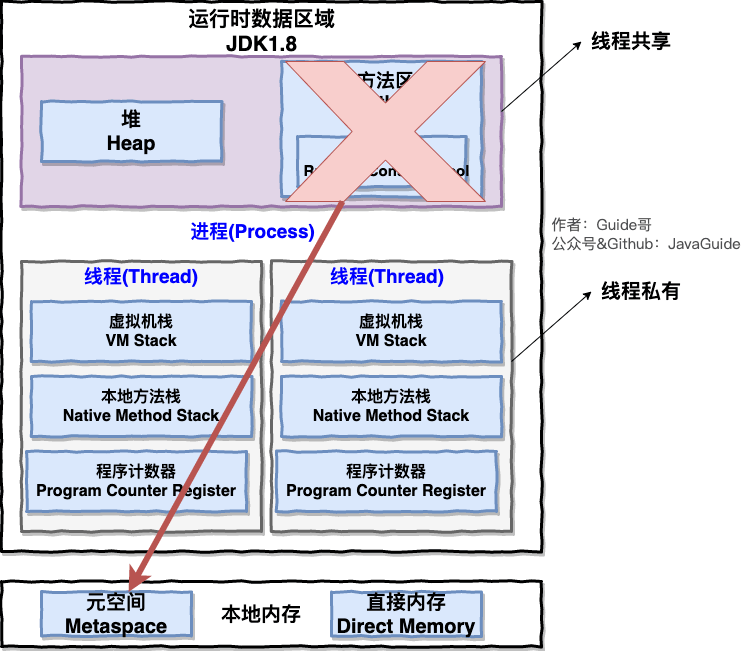
线程私有
程序计数器:指向下一条需要执行的字节码指令
虚拟机栈:Java 方法执行的内存模型,每次Java方法调用的数据都是通过虚拟机栈传递的。
本地方法栈:Native方法执行的内存模型,每次Native方法调用的数据都是通过本地方法机栈传递的。
线程共享
堆:存放对象实例
元空间【方法区】:存放常量、类信息、静态变量、JIT编译后的代码
直接内存:NIO中的基础
Jvm垃圾回收算法
回收区域:堆是需要回收的核心区域
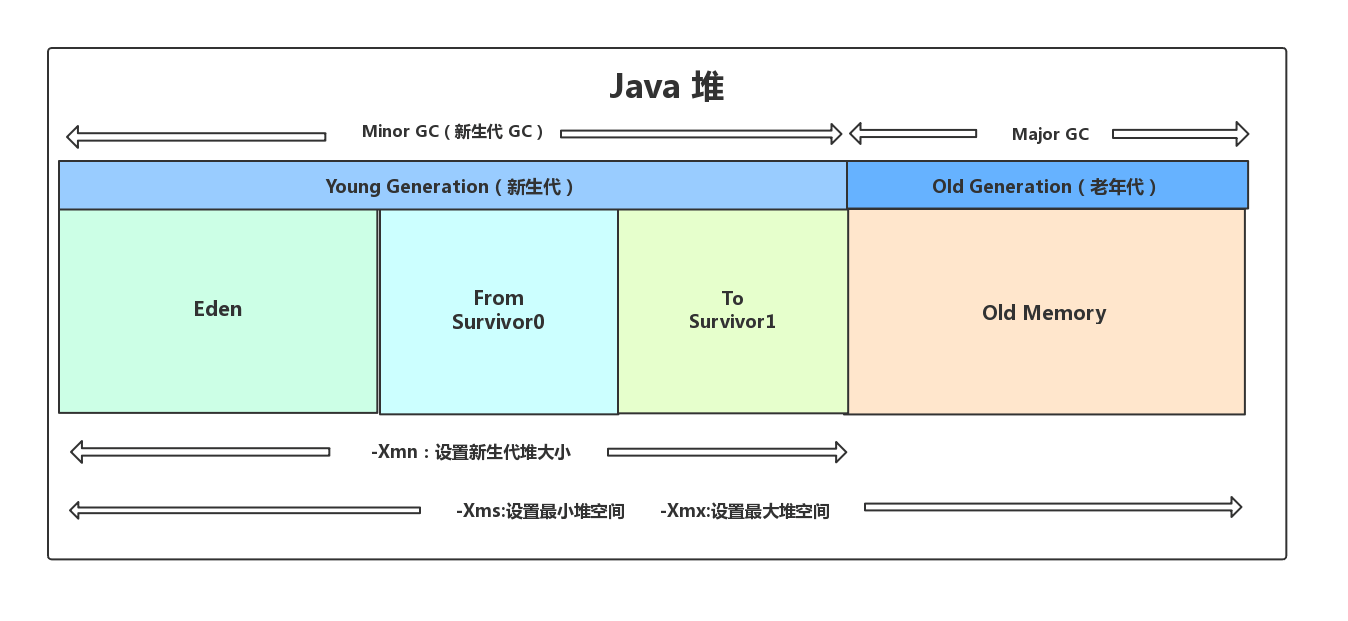
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 s0 或者 s1,并且对象的年龄还会加 1,当它的年龄增加到一定程度,就会被晋升到老年代中。
判断可回收:可达性分析,GCROOTS:类静态属性、常量、虚拟机栈中、本地方法栈中 引用的对象
垃圾收集算法:
- 标记清除【内存碎片问题】、标记整理【效率低】:用于老年代
- 标记复制:用于新生代,在回收时,将 Eden 和 Survivor 中还存活着的对象全部复制到另一块 Survivor 上,最后清理 Eden 和使用过的那一块 Survivor。
volatile关键字的原理与作用
- 作用:防止指令重排、保证内存可见性【不保证原子性:
i++由多个原子操作组成】 - 原理:禁止指令重排,在写操作后加入屏障指令,将本地内存中的共享变量值刷新到主内存,在读操作前加入屏障指令,从主内存中读取共享变量。
Java集合类(线程安全/不安全)
- StringBuilder是线程不安全的,而StringBuffer是线程安全的。
- ArrayList线程不安全,CopyOnWriteArrayList线程安全
- HashMap线程不安全,ConcurrentHashMap线程安全
- 并发队列:ConcurrentLinkedQueue、LinkedBlockingQueue、ArrayBlockingQueue、PriorityBlockingQueue、DelayQueue
【@】Synchronized和Lock的实现原理与区别
Synchronized:基于对象监视器锁,
monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置。【JVM层面】Lock:基于AQS队列【JDK层面】
区别:Lock 的高级功能:等待可中断、公平锁、多条件绑定
ConcurrentHashMap原理,如何保证线程安全
1.7
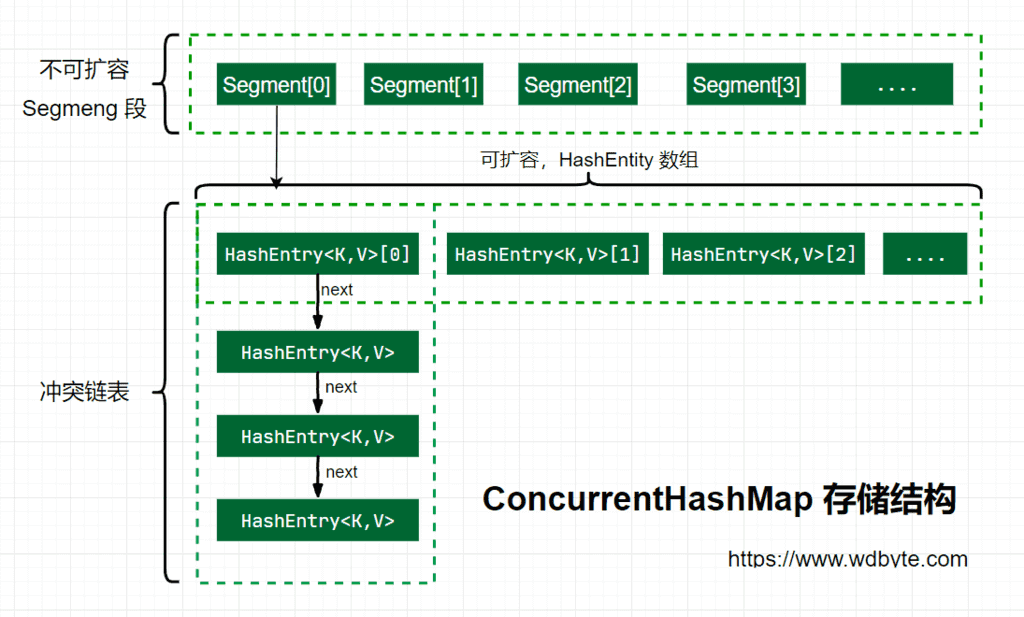
1.8
1.8抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
Java线程池核心参数与工作流程,拒绝策略
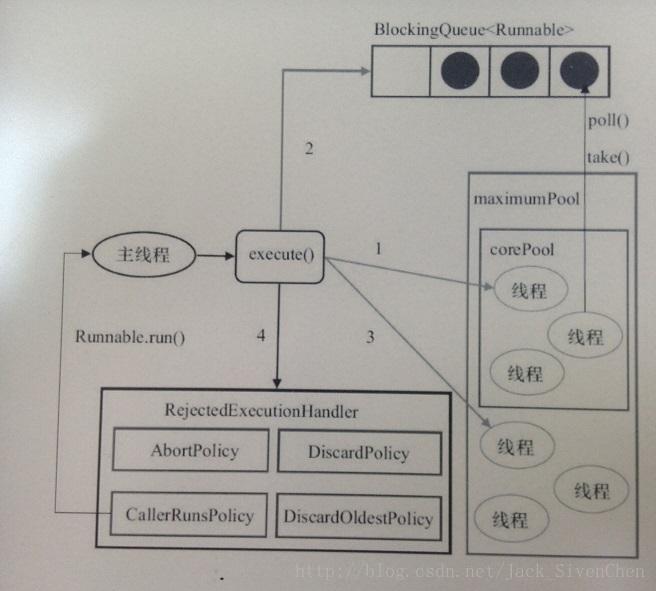
corepool、queue、maximumpool、reject四级处理keepAliveTime用于配置闲置线程最长存活时间,直到收缩到corePoolSize的大小reject有:抛出异常(abort)、由上层线程执行(callruns)、删除该任务(discard)、删除老任务(discardoldest)
【@】类加载机制
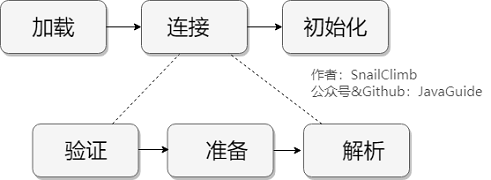
加载:获取二进制字节流=>生成方法区运行时数据结构=>生成class对象作为方法区数据入口
连接:验证、准备【初始化默认值】、解析【符号引用替换为直接引用,也就是得到类或者字段、方法在内存中的指针或者偏移量】
初始化:初始化方法 <clinit> ()
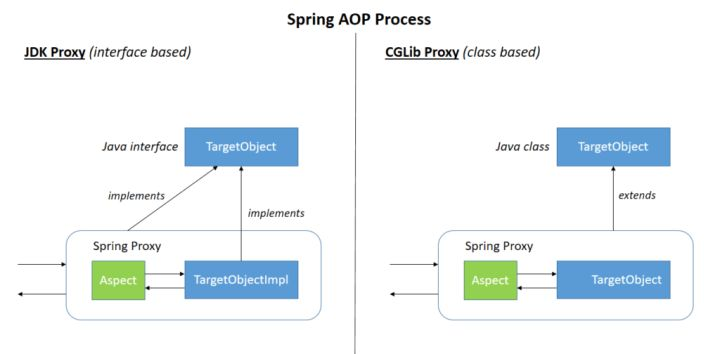
【@】SpringAOP的底层原理
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理,如下图所示:
动态代理:设计模式是代理模式【使用代理对象来代替对真实对象的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能】。本质上是通过类加载,然后修改类字节码,重新加载到JVM中,具体是通过反射完成。
数据库Mysql
Mysql的几种存储引擎
MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。MyISAM 不提供事务支持。
InnoDB 提供事务支持,具有提交(commit)和回滚(rollback)事务的能力。
MyISAM 不支持,而 InnoDB 支持。
Mysql的聚簇索引和非聚簇索引作用与区别
聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。
在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找。辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,再通过数据页中的Page Directory找到数据行。
索引的数据结构对比(hash、B树与B+树),为什么不用红黑树
hash表:不支持范围查找,一般不使用
红黑树的弊端:红黑树是二叉树!红黑树一个节点只能存出一个值,在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。
B树(多路平衡查找树):B树是一种自平衡的多叉搜索树,一个节点可以拥有两个以上的子节点,节点中的数据索引从左到右递增排列。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在O(logn)时间内完成。
B+树:
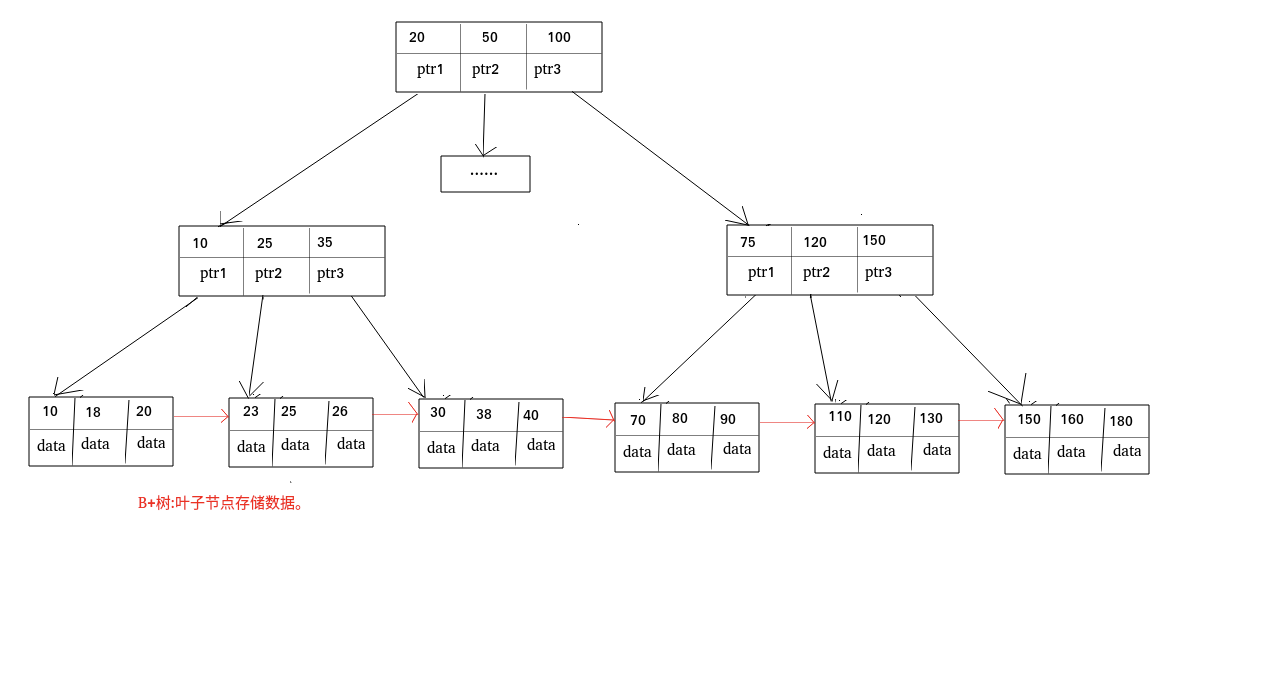
B树和B+树的区别:B 树的叶子节点都是独立的,B+树的叶子节点有一条引用链指向与它相邻的叶子节点。B+树只在叶子节点存储数据,查找速度稳定。
Mysql的默认隔离级别、不同等级隔离级别解决的问题与实现原理
1 | SELECT @@transaction_isolation; |
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ-UNCOMMITTED | √ | √ | √ |
| READ-COMMITTED | × | √ | √ |
| REPEATABLE-READ【默认隔离级别】 | × | × | √ |
| SERIALIZABLE | × | × | × |
脏读:在一个事务内读取到另一个事务中修改但未提交的数据。
不可重复读:在一个事务内读取到另一个事务中修改后提交的数据。
幻读:在一个事务内插入时遇到到另一个事务中插入后提交的数据。
不可重复读侧重表达 读-读,幻读则是说 读-写,用写来证实读的是鬼影。幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读。
解决方法:RR级别下只要对 SELECT 操作也手动加行(X)锁即可类似 SERIALIZABLE 级别。
1
2#FOR UPDATE 也会对此 “记录” 加锁
SELECT `id` FROM `users` WHERE `id` = 1 FOR UPDATE;
【TODO】Mvcc实现机制(RC和RR隔离级别下的区别)
InnoDB存储引擎对MVCC的实现 | JavaGuide
Mysql事务及特性
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
Mysql sql优化,慢Sql如何排查
mysql优化之 — 慢SQL分析 - 雪山上的蒲公英 - 博客园 (cnblogs.com)
索引失效的几种场景
索引失效的7种情况 - liehen2046 - 博客园 (cnblogs.com)
【@】数据库Redis
Redis基本数据类型
String、List、Set、Hash、SortedSet、BitMap
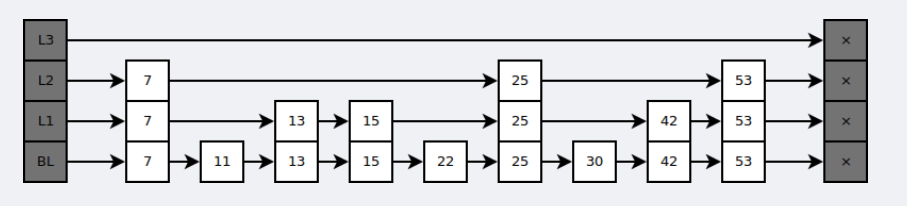
Redis底层数据结构
除了动态字符串、链表、字典【包含两个哈希表数,方便渐进式rehash】、还有维持有序性的跳表、维持不重复性的整数集合、节约内存的压缩列表
Redis持久化方式,RDB和AOF的区别与优劣势
RDB(Redis Database):将某个时间点的所有数据都存放到硬盘上。如果数据量很大,保存快照的时间会很长,由于是隔一段时间触发一次,实时性不是很好,系统崩溃后丢失的数据可能会很多。
AOF(Append Only File):每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到内存缓存 中,然后再根据 appendfsync 配置来决定何时将其同步到硬盘中的 AOF 文件。缺点是随着服务器写请求的增多,AOF 文件会越来越大。对此,Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
Redis如何实现分布式锁?
可以使用 Redis 自带的 SETNX 命令实现分布式锁:
使用 SETNX(set if not exist)指令插入一个键值对,如果 Key 已经存在,那么会返回 False,否则插入成功并返回 True。【和CAS一样】
SETNX 指令和数据库的唯一索引类似,保证了只存在一个 Key 的键值对,那么可以用一个 Key 的键值对是否存在来判断是否存于锁定状态。
EXPIRE 指令可以为一个键值对设置一个过期时间,从而避免了数据库唯一索引实现方式中释放锁失败的问题。
除此之外,还可以使用官方提供的 RedLock 分布式锁实现:
尝试从 N 个互相独立 Redis 实例获取锁;
使用了多个 Redis 实例来实现分布式锁,这是为了保证在发生单点故障时仍然可用。
计算获取锁消耗的时间,只有时间小于锁的过期时间,并且从大多数(N / 2 + 1)实例上获取了锁,才认为获取锁成功;
如果获取锁失败,就到每个实例上释放锁
计算机网络
Tcp与Udp区别
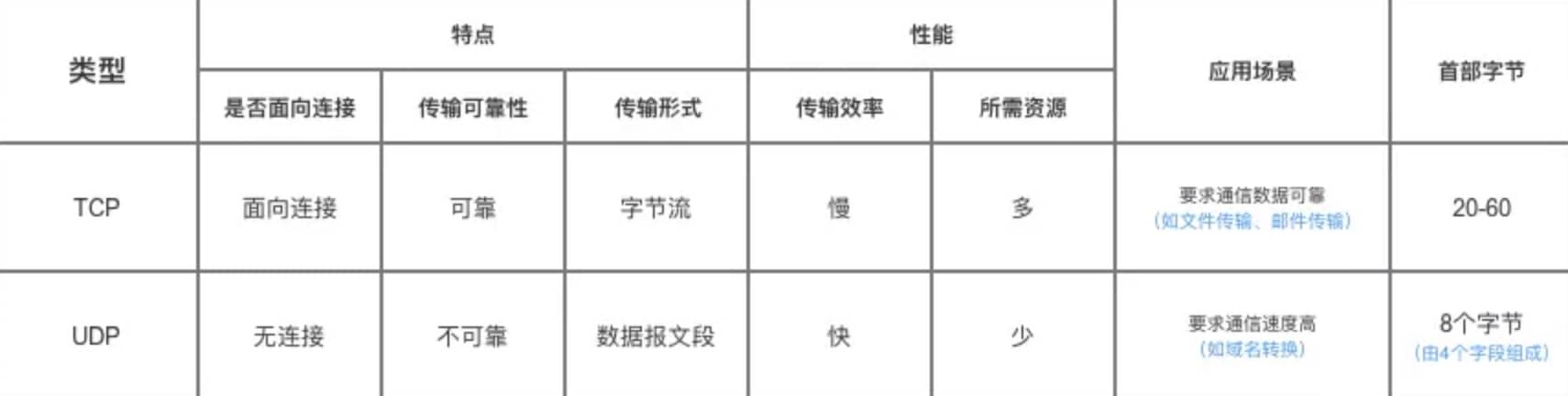
Tcp如何保证可靠传输
TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文段在超时时间内没有收到确认,那么就重传这个报文段。
浏览器上输入地址后的整个请求过程
- 浏览器缓存直接返回,否则
- DNS解析域名得到IP:浏览器缓存、hosts文件、本地域名服务器
- TCP连接:三次握手
- 发送HTTP请求(请求方法 请求头 cookie user-agent 等等 请求内容 表单等 ),获取HTTP响应(js、css、html、媒体文件) 【
Keep-Alive复用、TCP四次挥手】,浏览器渲染显示
OSI七层、五层模型,每一层的作用
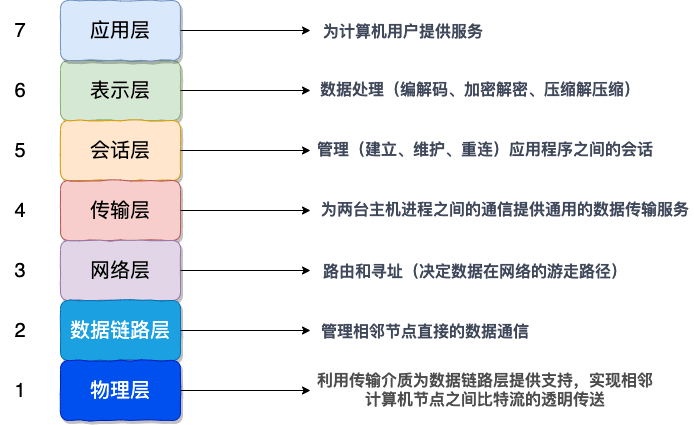
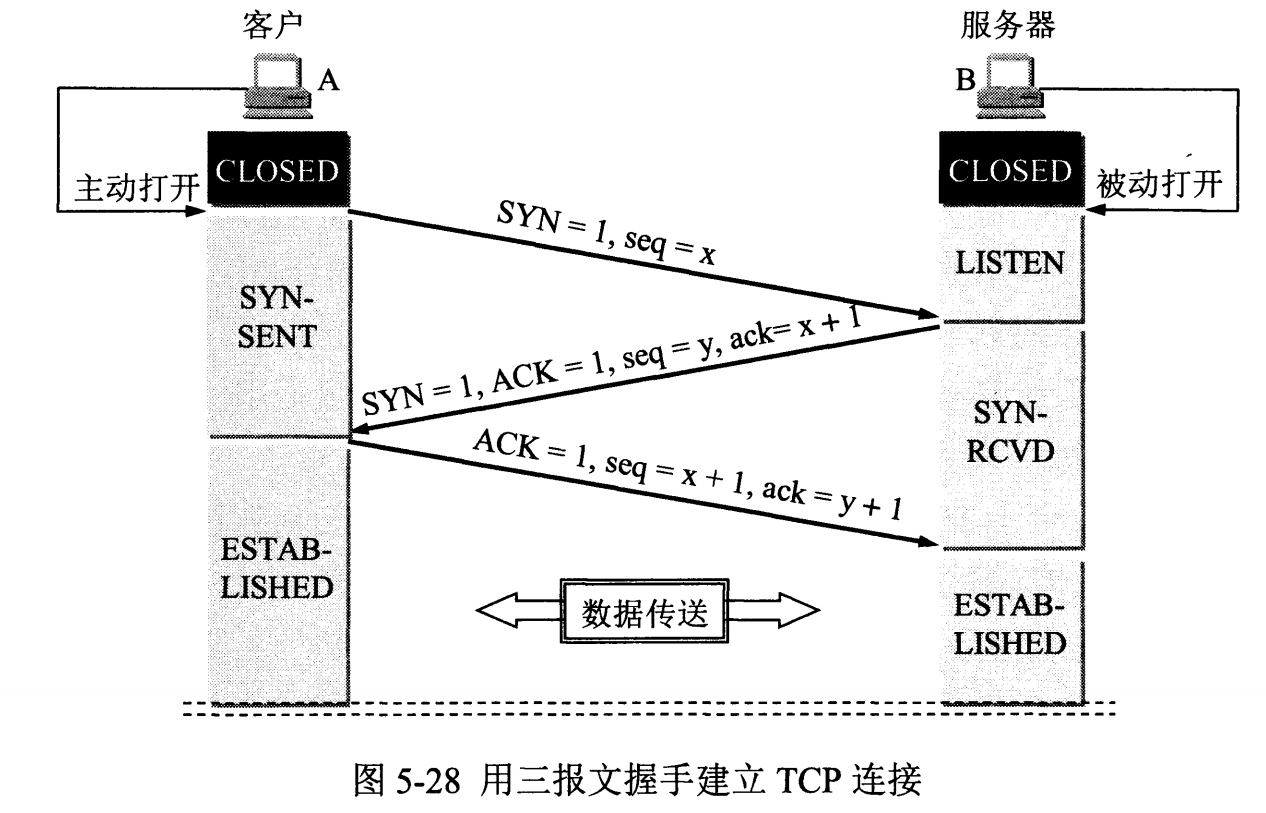
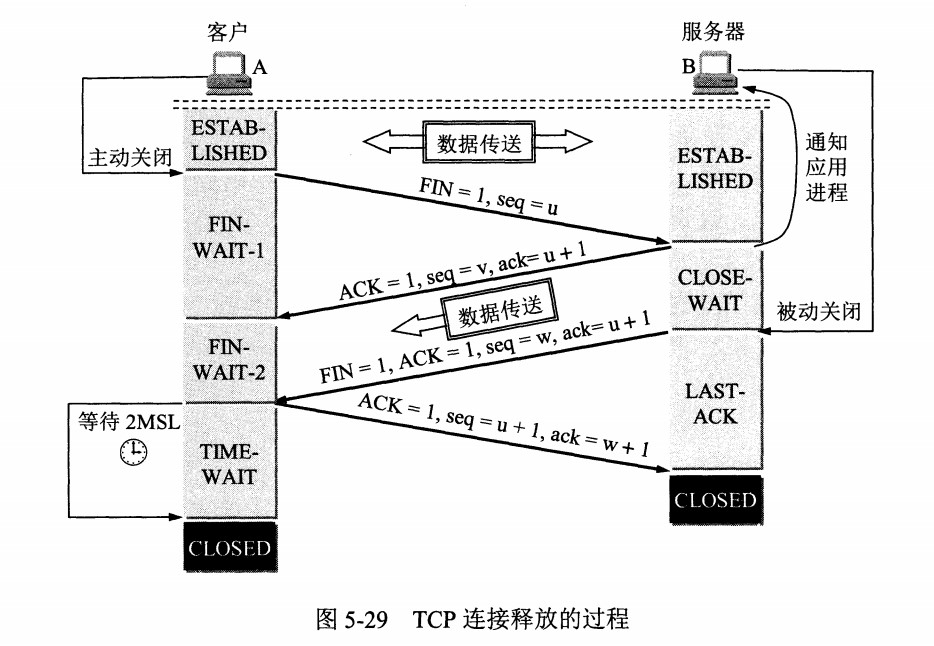
【@】TCP握手挥手过程及【状态变化】
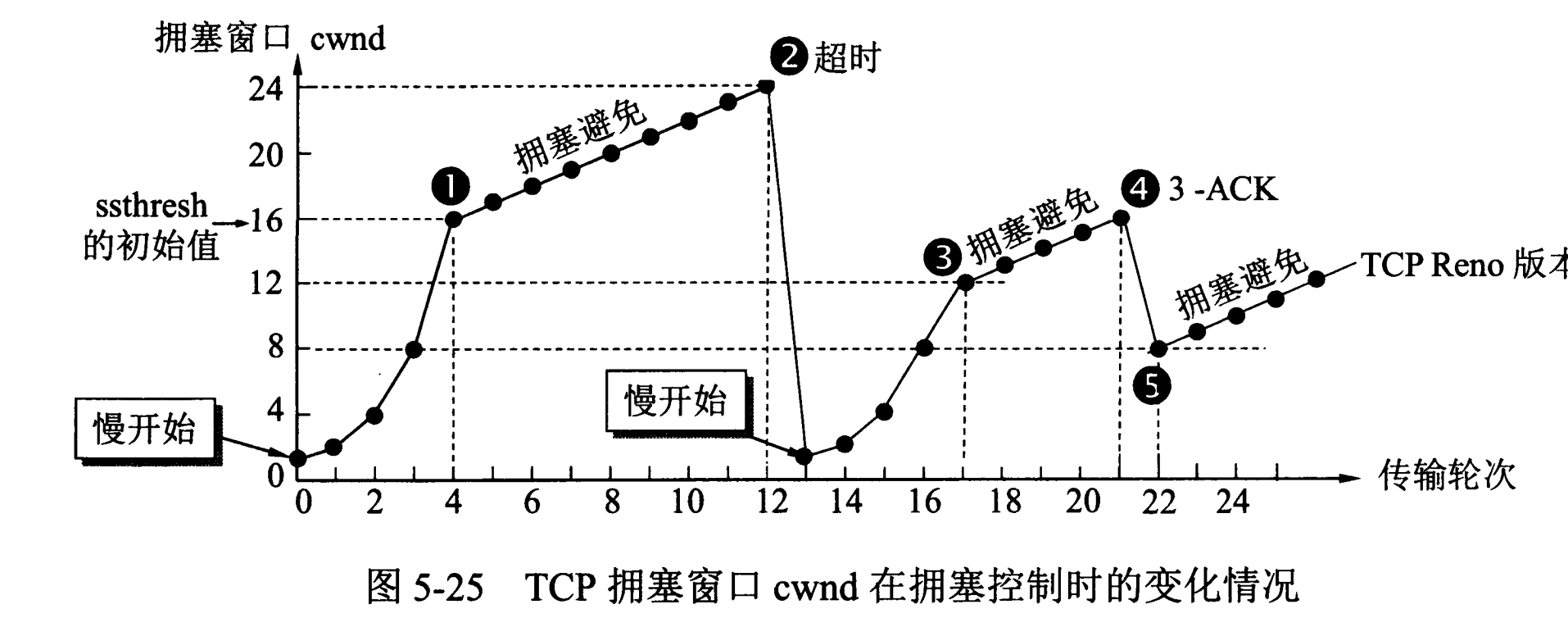
Tcp流量控制与拥塞控制
流量控制是为了控制发送方发送速率,保证接收方来得及接收。拥塞控制是为了降低整个网络的拥塞程度。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小。TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
Http、Https、两者区别
HTTPS 是基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。默认端口号是 443,HTTP默认端口号是80。HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
操作系统
进程与线程的区别
线程是调度的基本单位,进程是资源管理的基本单位。一般来说,进程之间是独立的,一个进程下会有若干个线程,然后这些线程共享进程资源,并极有可能相互影响。
补充:协程 - 廖雪峰的官方网站 (liaoxuefeng.com)
【@】进程之间通信方式
- 管道/匿名管道(Pipes) :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
- 有名管道(Names Pipes) : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循**先进先出(first in first out)**。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。【
ls | grep xxx】 - 信号(Signal) :信号是一种比较复杂的通信方式,用于通知接收进程某个事件;【
kill -9 pid】 - 消息队列(Message Queuing) :消息队列是消息的链表,消息队列有以下优点:可以独立于读写进程存在,不需要进程自己提供同步方法,读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
- 信号量(Semaphores) :信号量是一个计数器。信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
- 共享内存(Shared memory) :多个进程可以访问和更新同一块内存空间。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最快的进程间通信方式。
- 套接字(Sockets) : 套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点。
CAS操作原理和实现
CAS (compareAndSwap),中文叫比较交换,是一种无锁原子算法,映射到操作系统就是一条CPU的原子指令,其作用是让CPU先进行比较两个值是否相等,然后原子地更新某个位置的值,其实现方式是基于硬件平台的汇编指令。CAS 是实现自旋锁的基础,CAS 利用 CPU 指令保证了操作的原子性,以达到锁的效果,至于自旋呢,看字面意思也很明白,自己旋转,翻译成人话就是循环,一般是用一个无限循环实现。这样一来,一个无限循环中,执行一个 CAS 操作,当操作成功,返回 true 时,循环结束;当返回 false 时,接着执行循环,继续尝试 CAS 操作,直到返回 true。
死锁的产生条件与解决方案
产生条件:
- 互斥
- 不可抢占
- 申请等待
- 环
解决:
- 鸵鸟
- 死锁检测【有向图环形检测、银行家算法】与死锁恢复【抢占、回滚、kill】
- 死锁预防:破坏条件
- 死锁避免:银行家算法