网络数据的基本单位总是字节。Java NIO 提供了ByteBuffer 作为它的字节容器,但是这个类使用起来过于复杂,而且也有些繁琐。Netty 的ByteBuffer 替代品是ByteBuf,一个强大的实现,既解决了JDK API 的局限性,又为网络应用程序的开发者提供了更好的API。ByteBuf本质的原理就是引用了一段内存,这段内存可以是堆内也可以是堆外的,然后用引用计数来控制这段内存是否需要被释放,使用读写指针来控制对 ByteBuf 的读写,可以理解为是外观模式的一种使用。
基本结构
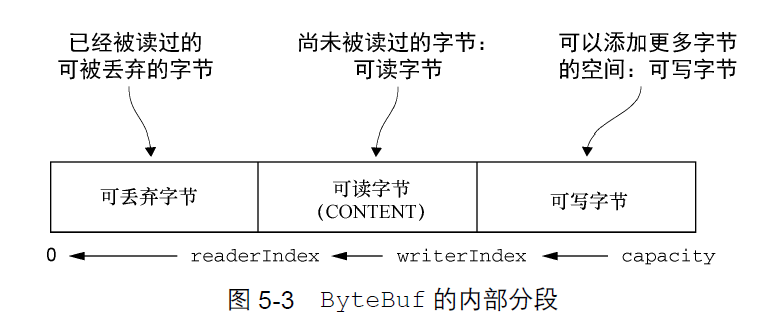
ByteBuf是一个字节容器,容器里面的的数据分为三个部分,第一个部分是已经丢弃的字节,这部分数据是无效的;第二部分是可读字节,这部分数据是ByteBuf的主体数据, 从ByteBuf里面读取的数据都来自这一部分;最后一部分的数据是可写字节,所有写到ByteBuf的数据都会写到这一段。以上三段内容是被两个指针给划分出来的,从左到右,依次是读指针(
readerIndex)、写指针(writerIndex),然后还有一个变量capacity,表示ByteBuf底层内存的总容量。从
ByteBuf中每读取一个字节,readerIndex自增1,ByteBuf里面总共有writerIndex-readerIndex个字节可读, 由此可以推论出当readerIndex与writerIndex相等的时候,ByteBuf不可读。写数据是从
writerIndex指向的部分开始写,每写一个字节,writerIndex自增1,直到增到capacity,这个时候,表示ByteBuf已经不可写了
ByteBuf里面其实还有一个参数maxCapacity,当向ByteBuf写数据的时候,如果容量不足,那么这个时候可以进行扩容,直到capacity扩容到maxCapacity,超过maxCapacity就会报错
API
容量
| 名 称 | 描 述 |
|---|---|
| capacity() | 表示 ByteBuf 底层占用了多少字节的内存(包括丢弃的字节、可读字节、可写字节) |
| maxCapacity() | 表示 ByteBuf 底层最大能够占用多少字节的内存,当向 ByteBuf 中写数据的时候,如果发现容量不足,则进行扩容,直到扩容到 maxCapacity,超过这个数,就抛异常 |
| readableBytes() | 表示 ByteBuf 当前可读的字节数,它的值等于 writerIndex-readerIndex,如果两者相等,则不可读,isReadable() 方法返回 false |
| writableBytes() | ByteBuf 当前可写的字节数,它的值等于 capacity-writerIndex,如果两者相等,则表示不可写,isWritable() 返回 false,但是这个时候,并不代表不能往 ByteBuf 中写数据了, 如果发现往 ByteBuf 中写数据写不进去的话,Netty 会自动扩容 ByteBuf,直到扩容到底层的内存大小为 maxCapacity,而 maxWritableBytes() 就表示可写的最大字节数,它的值等于 maxCapacity-writerIndex |
索引管理
| 名 称 | 描 述 |
|---|---|
| readerIndex() | 返回当前的读指针 |
| writeIndex() | 返回当前的写指针 |
| markReaderIndex() | 把当前的读指针保存起来 |
| resetReaderIndex() | 把当前的读指针恢复到之前保存的值 |
读写操作
有两种类别的读/写操作:
get()和set()操作,从给定的索引开始,并且保持索引不变;read()和write()操作,从给定的索引开始,并且会根据已经访问过的字节数对索引进行调整。
基于读写指针和容量、最大可扩容容量,衍生出一系列的读写方法。其中比较重要的有:
| 名 称 | 描 述 |
|---|---|
| readByte() | 返回当前readerIndex 处的字节,并将readerIndex 增加1(从 ByteBuf 中读取一个字节) |
| writeByte(int) | 在当前writerIndex 处写入一个字节值,并将writerIndex 增加1(往 ByteBuf 中写一个字节) |
| readBytes(destination byte[]) | 把 ByteBuf 里面的数据全部读取到 destination (ByteBuf->destination) |
| writeBytes(source byte[]) | 把字节数组 source 里面的数据写到 ByteBuf(source->ByteBuf) |
类似的 API 还有 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() 与 readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble() ,这里就不一一赘述了。
内存管理
由于 Netty 可以使用堆外内存,而堆外内存是不被 jvm 直接管理的,也就是说申请到的内存无法被垃圾回收器直接回收,所以需要我们手动回收,否则会造成内存泄漏。Netty 的 ByteBuf 是通过引用计数的方式管理的,如果一个 ByteBuf 没有地方被引用到,需要回收底层内存。默认情况下,当创建完一个 ByteBuf,它的引用为1,然后每次调用 retain() 方法, 它的引用就+1, release() 方法原理是将引用计数-1,减完之后如果发现引用计数为0,则直接回收 ByteBuf 底层的内存。
池化
为了降低分配和释放内存的开销,Netty 通过 ByteBufAllocator 实现了ByteBuf 的池化,它可以用来分配我们所描述过的任意类型的ByteBuf 实例(直接内存、堆内存)。
1 | //从Channel 获取一个到 ByteBufAllocator 的引用 |
一般使用buffer(int initialCapacity, int maxCapacity);返回一个基于堆或者直接内存存储的ByteBuf。
复制
slice()、duplicate()、copy()三者的返回值都是一个新的 ByteBuf 对象:
slice()方法从原始ByteBuf中截取一段,这段数据是从readerIndex到writeIndex,同时,返回的新的ByteBuf的最大容量maxCapacity为原始ByteBuf的readableBytes()duplicate()方法把整个ByteBuf都截取出来,包括所有的数据,指针信息slice()方法与duplicate()方法不会拷贝数据,它们只是通过改变读写指针来改变读写的行为。底层内存以及引用计数与原始的ByteBuf共享,也就是说返回的ByteBuf调用write系列方法都会影响到原始的ByteBuf,但是它们都维持着与原始ByteBuf不同的读写指针。copy()会直接从原始的ByteBuf中拷贝所有的信息,包括读写指针以及底层对应的数据,因此,copy()返回的ByteBuf中写数据不会影响到原始的ByteBufretainedSlice()与retainedDuplicate()它们的作用是在截取内存片段的同时,增加内存的引用计数。
多个 ByteBuf 可以引用同一段内存,而Netty会通过引用计数来控制内存的释放,应当遵循谁 retain() 谁 release() 的原则。我们建议,在一个函数体里面,只要增加了引用计数(包括 ByteBuf 的创建和手动调用 retain() 方法),就必须调用 release() 方法,否则往往会出现内存泄露的问题。